
Generative Artificial Intelligence (GenAI) has often been praised or dismissed due to poor results. A lot seems to depend on the task. I try to use it for tabulating books for which only photos of the covers are available – 6500 photos! Nobody would have done the task manually.

I analyzed a hashtag on Mastodon and for the first time handed over large amounts of data to an LLM (ChatGPT 4o). The target was the hashtag #20books on Mastodon under which thousands of books are posted that have particularly influenced the users there.
It was very easy to get the content, the analysis had its pitfalls, which I would like to describe here.
Here is the link to the analysis of the books:
https://digi-ing.de/finding-cool-books-on-mastodon-by-analyzing-over-6000-posts
The method
Most Mastodon instances have a REST API that can be used to query individual posts, called toots. I did this for the hashtag “20books” and got a decent number of results:
number of toots processed: 6682
number of toots with media: 6376
number pictures: 6543This means that there are around 6500 images of book covers that can now be analyzed with ChatGPT.
Testing in the Playground – impressive results
I initially tested with just a few books in the Playground until I had a prompt that delivered great results for these books.
The Promt:
You are an assistant for the task of extracting information form pictures of book covers. You will receive images of book covers. Please analyze the picture to identify the following details: 1. The author’s name, 2. The book’s title, 3. The date of first publishing, 4. The genre and 5. sub-genre. Create a confidence score from 0 (just a guess) to 100 (absolutely certain) that describes how confident you are in the accuracy of the details identified. Add the score to details analyzed. Output the results as a .csv. No other text output. All in one line. No Header of the csv. Values shall not be embedded in apostrophes. date format yyyy. If you cannot identify a book in the picture return the Text: No Value extraction possible”
Impressive results were delivered even in difficult cases.
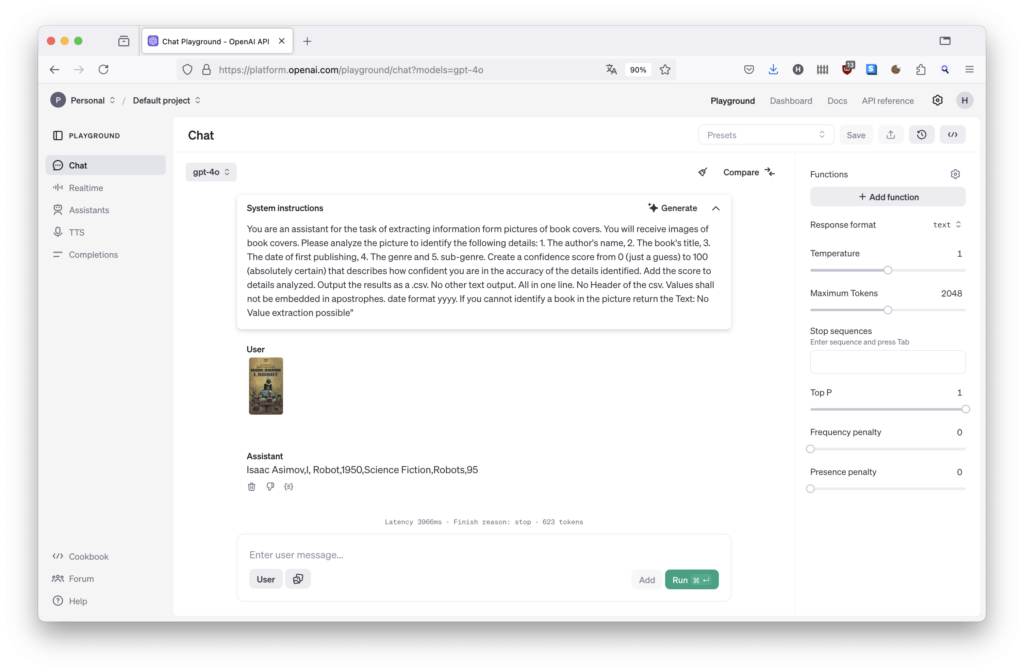
Ultimately, the task is “Recognize the content of the image and search for the metadata” and the LLM certainly knows this. After all, all these books are available on the Internet.
ALL IN: Evaluate all images – sobering up
Encouraged by the good results, I now submitted all 6500 images for analysis via the OpenAI API. After a few hours, not only the results but also the disillusionment were there. There were some deviations that I had to correct afterwards – sometimes completely manually. I have summarized the problems in three categories.
Error category 1) Different spellings for the same terms
Each analysis produces a random spelling of the same terms. For example, “non-fiction” becomes “non-fiction” or “non-fiction”. “Moby-Dick” and ‘Moby Dick’ also appear. This doesn’t bother the human reader, but it makes a static analysis, as I intend to do, very difficult.
The different returns in the case of an unidentifiable date are absolutely sobering – 65 different terms were returned for this identical situation!
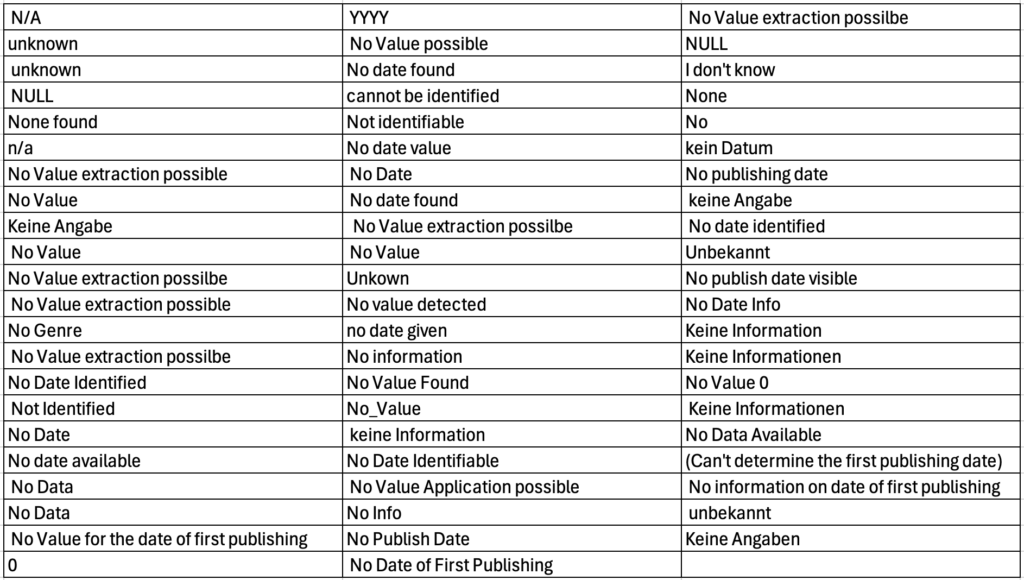
Error category 2) Error in the execution of the prompt: Commas not consistently placed in the csv
Approx. 150 entries were set completely without commas, others have too many or too few commas. This does not look good when creating csv data (written out as comma-separated values!).
Error category 3) Ignoring the prompt: The order or syntax of the results is repeatedly changed
For example, three genre subdivisions are returned where two were asked for or several authors are separated with commas where only one value is provided for author.
Sometimes the parameters are written out together with the results, e.g. “Sub-genre: Comic”.
The worst thing, however, is the swapping of title before author in hundreds of entries. This is difficult to correct and occurs frequently.
Is there no better way?
If I were to start the task again, I would change two things in particular:
First, an immediate check of the return. If, for example, the syntax is incorrect, the result is deleted and simply asked again with the same data. Although this leads to higher token consumption, it should reduce rework.
Secondly, it makes sense to let ChatGPT optimize itself. In other words, collect errors and ask for an improved prompt. I did this and they suggested, among other things, a better structuring of the return values and the addition of an example result:

All of this improves quality, but cannot solve all of the problems mentioned above.
Conclusion
GenAI is an exciting tool. It makes work possible that no one else has time for, or would you have sat down and manually tabulated 6500 book covers?
However, checking the results with great care is essential. A considerable amount of time and resources must be planned for this. Control mechanisms should be considered and built into the editing process wherever possible.
I had a lot of fun with this mini-project and I think the results are quite nice
