Spreadsheet programs are used in most companies and across departmental boundaries. The versatility of applications is enormous.
The question of the accuracy of the results is often not asked.
However, incorrectly evaluated measurement data or incorrect information on company key figures can have serious consequences.
The question becomes even more pressing when you consider that, unlike software that is created as a product, Excel spreadsheets are not usually not tested. In fact, a spreadsheet, including cell links, is often created by a single person.
A meta-study by the University of Hawaii examined the frequency of errors in spreadsheets of large corporations. It was shown that 3.9% of all formulas are incorrect.
This may not sound like much, but if you consider how many cells are filled for many applications, the significance becomes clear.
The following figure shows the probability of having at least one error in a document over the number of cells with formulas entered by the user.
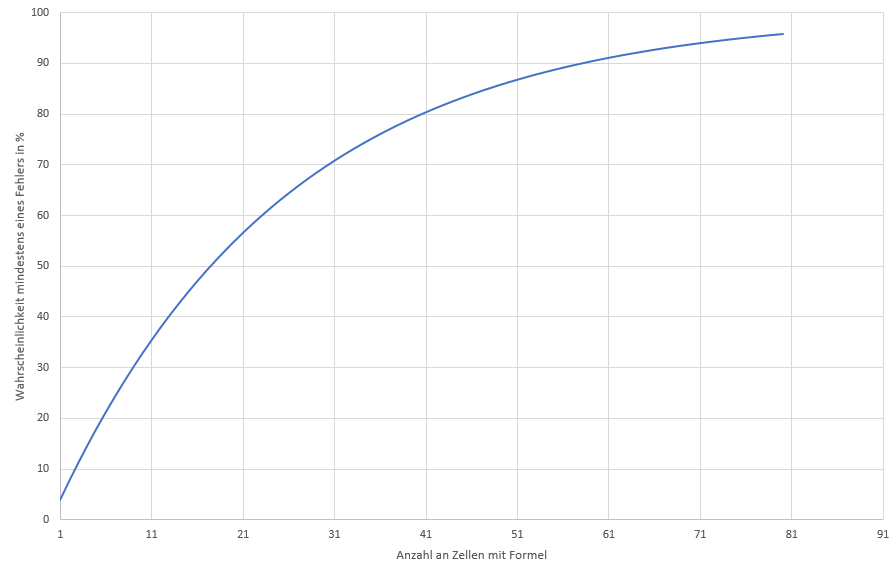
With one cell, the probability of an error is the 3.9% stated in the study. It increases rapidly as more cells are entered.
With just nine cells entered, the probability of an error is 30%
This clearly shows that a large number of the tables used every day contain errors. With unclear consequences. At best, no critical results are affected or several inaccuracies cancel each other out. However, incorrect decisions are probably also made on the basis of incorrect tables.
The motivation to improve this situation should therefore be there. However, the implementation is not so easy, as debugging is not provided for in spreadsheet programs. Breakpoints for checking intermediate results cannot be set. Instead, the calculation is executed in full each time a new entry is made. Test cases cannot be easily implemented either; I am not aware of any test environments.
There are measures that can be taken to reduce the likelihood of errors
- Divide calculations into sub-steps and evaluate partial results
The task is divided by the creator into subtasks with corresponding partial results. These serve as a substitute for breakpoints in the program flow. The partial results are checked for correctness when (synthetic) known data is entered.
- Review of the table by a second person
The creator is not the most suitable person to check their own work. Therefore, a second person should carry out the review.
A clear task and the commented implementation are required. Both will often not be available in practice, so this solution must also be prepared.
- Checking with a second tool
If a solution is programmed twice, the probability of producing errors with identical effects is low. This method is used when creating security-relevant applications. It is time-consuming, but safe.
- Formally include tables in software testing
If the company produces software as a product, the tables can be formally included in the process. Together with the relevant specialist department, a concept can be created that is adapted to the company and the risk.
[Update] The European Spreadsheet Risks Interest Group provides further information on improving Excel spreadsheets.
For example, best practices are described in this somewhat older paper. Unfortunately, the fact that the paper dates back to 2005 and most of the points are still up to date is no sign of rapid change in this field.