In supervised learning, the correct answer to a question is provided together with the task. The logic according to which the data is to be processed is therefore known. This data set is called training data. The idea of a human explaining things to a machine applies well here.
The task can be set in different ways:
- Regression: Find a mathematical relationship that describes the current situation well
- Classification: Sort existing data according to assigned criteria
An example to better understanding
Let’s assume that we manufacture a certain printed circuit board with
components in large-scale production and there are different voltages between two
between two test points on the card. In addition, some cards
function as expected (“OK”), others do not (“NOK”). During the
production, there is a random fluctuation in the soldering temperature due to the
soldering temperature.
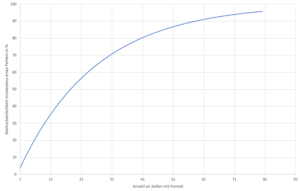
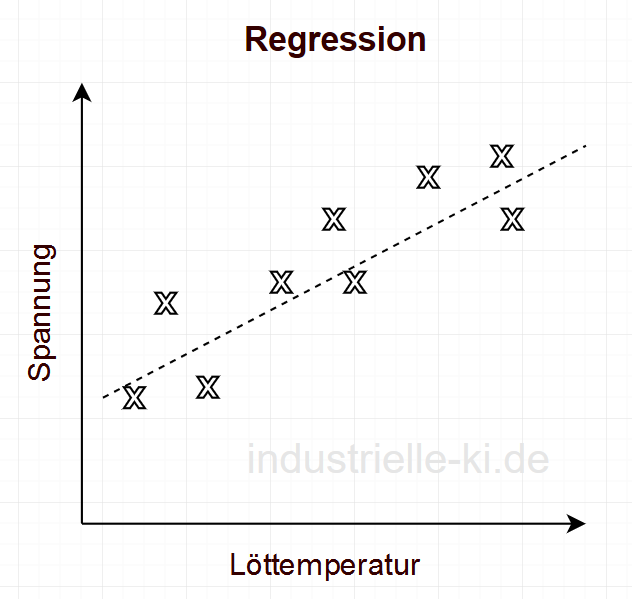
A regression could be used to describe the relationship between the
between the soldering temperature and the test voltage, see Figure 1.
function of the manufactured components. If the voltage limits for operation are known, however, this statement can be
simply be made.
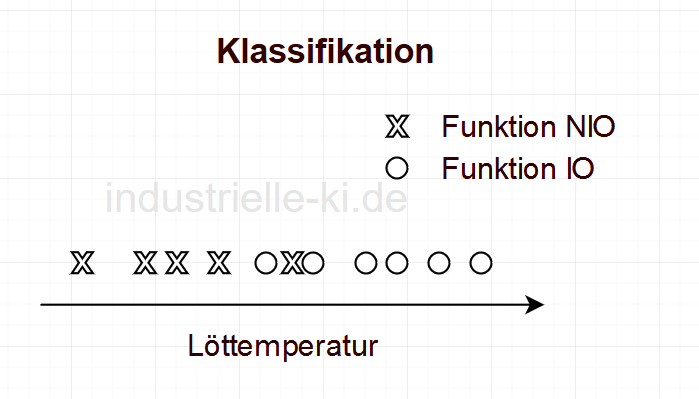
If we want to classify in the same example, the result could look like the following figure. OK and NOK components are assigned to the influencing variable. If a sufficient amount of data is available, the result is the probability of a component failing at a certain soldering temperature.
In this simple example, the problems can also be described using statistics, but it must be borne in mind that the number of influencing and target variables can be any number. If the variables are still independent of each other, the attractiveness of machine learning increases and that of statistics decreases.
Issue: Overfitting
There is one particular danger with supervised learning: overfitting. This is when non-causal influencing variables are incorporated into the model. If, in addition to the values for voltage and soldering temperature used in our example, variables that are certainly or probably not causal are also transferred, the model is also trained on these. These could be SAP handles, the packaging ID of the installed components or the time of day, for example. In the subsequent application, these patterns would then also be recognized and the quality of the result would deteriorate.