Beim Supervised Learning („Überwachtes Lernen“) wird die richtige Antwort auf eine Fragestellung zusammen mit der Aufgabe übergeben. Die Logik nach die Daten bearbeitet werden sollen ist also bekannt. Diese Datensatz nennt man Trainingsdaten. Die Vorstellung nach der ein Mensch einer Maschine Dinge erklärt trifft hier gut zu.
Die Aufgabe kann unterschiedlich gestellt werden:
- Regression: Finde einen mathematischen Zusammenhang, die die vorliegenden Situation gut beschreibt
- Klassifikation: Sortieren vorliegenden Daten nach vergebenen Kriterien
Ein Beispiel zum besseren Verständnis
Nehmen wir an, wir stellen eine bestimmte Leiterkarten mit verschiedenen Bauteilen in Großserie her und es zeigen sich unterschiedliche Spannungen zwischen zwei Prüfpunkte auf der Karte. Zudem weisen einige Karten die erwartete Funktion auf („IO“), andere tun dies nicht („NIO“). Bei der Herstellung kommt es anlagenbedingt zu einer zufälligen Schwankung der Löttemperatur.
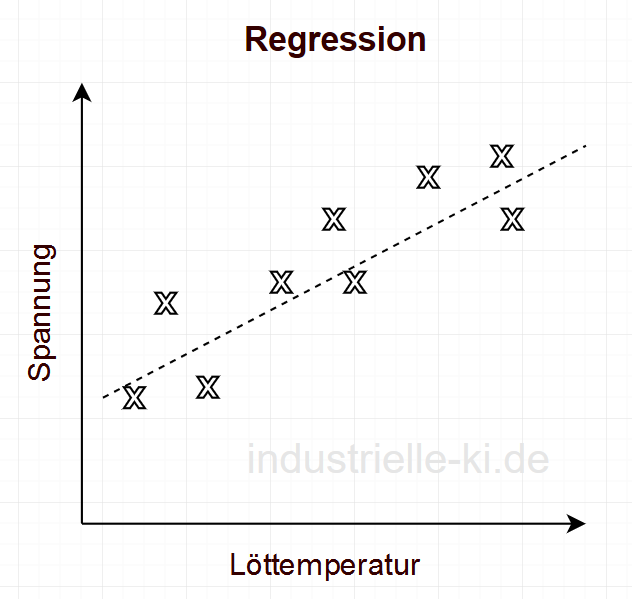
Über eine Regression könnte der Zusammenhang zwischen der Löttemperatur und der Prüfspannung beschrieben werden, siehe Abbildung 1. Über die Funktion der hergestellten Bauteile wird hier noch nichts ausgesagt. Sind die Grenzen der Spannung für den Betrieb bekannt, so kann diese Aussage jedoch einfach getroffen werden.
Bei einem linearen Zusammenhang ist dieser Zusammenhang leicht auch ohne Machine Learning zu bestimmen. Wird das Modell jedoch komplexer durch weitere Einflussgrößen und nicht lineare Zusammenhänge, so spielt Supervised Learning seine Vorteile voll aus.
Wollen wie denselben Sachverhalt einer Klassifikation unterziehen, so könnte das Ergebnis wie in folgender Abbildung aussehen. IO und NIO Bauteile werden der Einflussgröße zugeordnet. Liegen hinreichend viele Daten vor, so ist das Ergebnis die Wahrscheinlichkeit mit der ein Bauteil bei einer bestimmten Löttemperatur ausfällt.
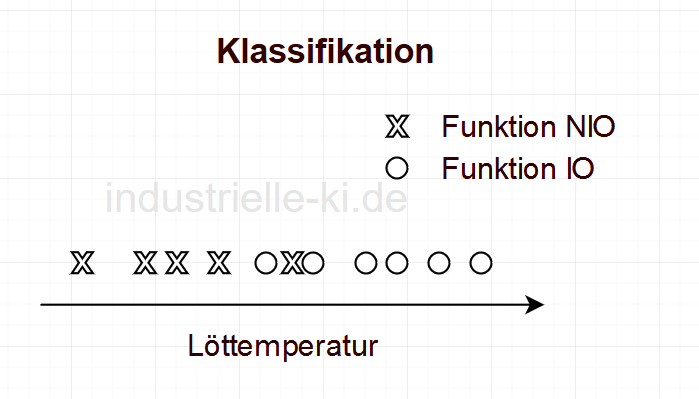
In diesem einfachen Beispiel sind die Probleme auch mittels Statistik beschreibbar, es muss jedoch bedacht werden, dass die Anzahl der Einfluss- und der Zielgrößen eine beliebige Anzahl annehmen kann. Sind die Größen dann noch unabhängig voneinander, nimmt die Attraktivität des Machine Learnings zu und die der Statistik ab.
Gefahrenquelle Overfitting
Eine Gefahr besteht beim Supervised Learning ganz besonders, das sogenannte Overfitting. Dabei werden in das Modell nicht ursächliche Einflussgrößen eingebaut. Werden neben den in unserem Beispiel verwendeten Werten für Spannung und Löttemperatur auch Größen übergeben die sicher oder vermutlich nicht ursächlich sind wird das Modell auch auf diese trainiert. Das könnten beispielsweise SAP-Handles, Verpackungs-ID der verbauten Komponenten oder die Tageszeit sein. In der späteren Anwendung würden dann auch diese Muster erkannt werden und die Qualität des Ergebnisses verschlechtern.
Könnt ihr euch Anwendungsfälle vorstellen? Habt ihr schon Anwendungen mit Supervised Learning umgesetzt? Schreibt es gerne in die Kommentare.