
Ich bin auf Mastodon über den Hashtag 20books gestolpert, unter dem Leute die Bücher posten, die sie am meisten beeinflusst haben. Die Idee, die hinter dem Hashtag steckt, ist im ersten Beitrag zu sehen, den ich finden konnte:

Diese „Challenge“, jeden Tag ein Buch zu posten, lief schon eine ganze Weile mit zahlreichen Teilnehmern, und ich habe mich gefragt, ob ich coole Bücher verpasst habe, die ich meiner Leseliste hinzufügen sollte. Und so wurde die Idee geboren, alle Bücher aufzulisten und zu durchsuchen. Das Problem ist, dass es nur Bilder von Covern und keine Metadaten in den Beiträgen gibt.
So wurde die Datenextraktion durchgeführt
Nach einigen erfolglosen Versuchen mit Optical Character Recognition oder der Verwendung des ALT-Textes der Bilder, dachte ich mir, dass dies meine erste echte Aufgabe für GenAI sein könnte. Informationen aus Bildern zu extrahieren und mit dem Wissen aus dem Internet zu kombinieren, schien mir eine gute Aufgabe für dieses Tool zu sein.
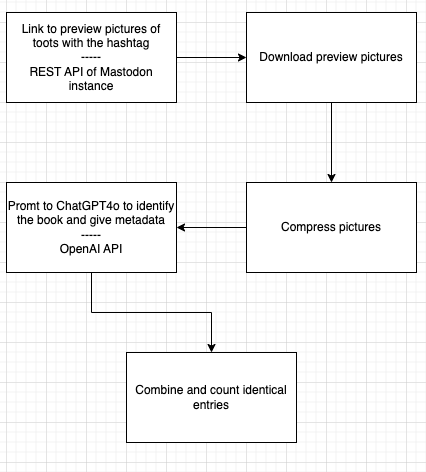
Kurz gesagt, ich lud die Vorschaubilder aller Toots herunter, die den Hashtag enthielten. Das war nicht schwer, da die meisten Mastodon-Instanzen über eine REST-API verfügen, über die man Toots mit einem bestimmten Hashtag abfragen kann. Aus dem Ergebnis habe ich den Link zum Bild extrahiert.
Eine Komprimierung war notwendig, um die Größe für den nächsten Schritt zu reduzieren, nämlich ChatGPT zu bitten, das Bild zu analysieren. Ich bat dieses LLM, den Autor, den Titel, das Jahr der Erstveröffentlichung, das Genre und das Subgenre zurückzuliefern, indem ich die OpenAI API benutzte, um die Abfrage für alle Bilder zu stellen.
Anschließend habe ich nach identischen Einträgen gesucht und sie gezählt.
Einschränkungen
Dieses Verfahren ist mit einigen Einschränkungen verbunden, von denen die meisten mit der Verwendung von GenAI zusammenhängen
FALSCHE ERKENNUNG
Ich habe die Ergebnisse beispielhaft überprüft und kaum Fehler gefunden. Ein 100%ig korrekte Zuordnung ist es nicht.
FALSCHE METADATEN
Besonders die Jahreszahl musste manuell korrigiert werden und ich habe vermutlich nicht alle Fehler gefunden.
FALSCHER SYNTAX
Falsche Reihenfolge (z.B. Autor und Titel vertauscht), fehlendes Komma, fehlende Werte etc.
BUCH IN MEHREREN SPRACHEN VERÖFFENTLICHT
Das habe ich nicht korrigiert. Somit wird ein Buch, das in mehrmals in verschiedenen Sprachen gepostet wurde, als mehrere Bücher gezählt wird.
Ich finde die Ergebnisse trotzdem schlüssig, auch wenn ich weiß, dass sie nicht 100%ig korrekt sind.
Die Ergebnisse
Insgesamt habe ich 6682 Toots analysiert und konnte 5904 Bilder extrahieren.
Das älteste Bild ist vom 20. MAI 2024 und ich habe am 31. AUGUST 2024 aufgehört zu sammeln.
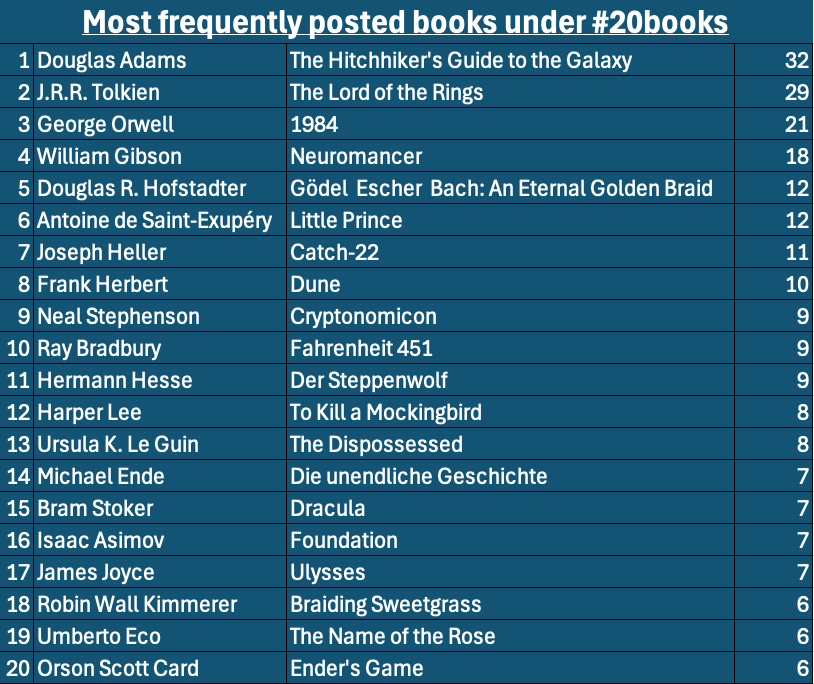
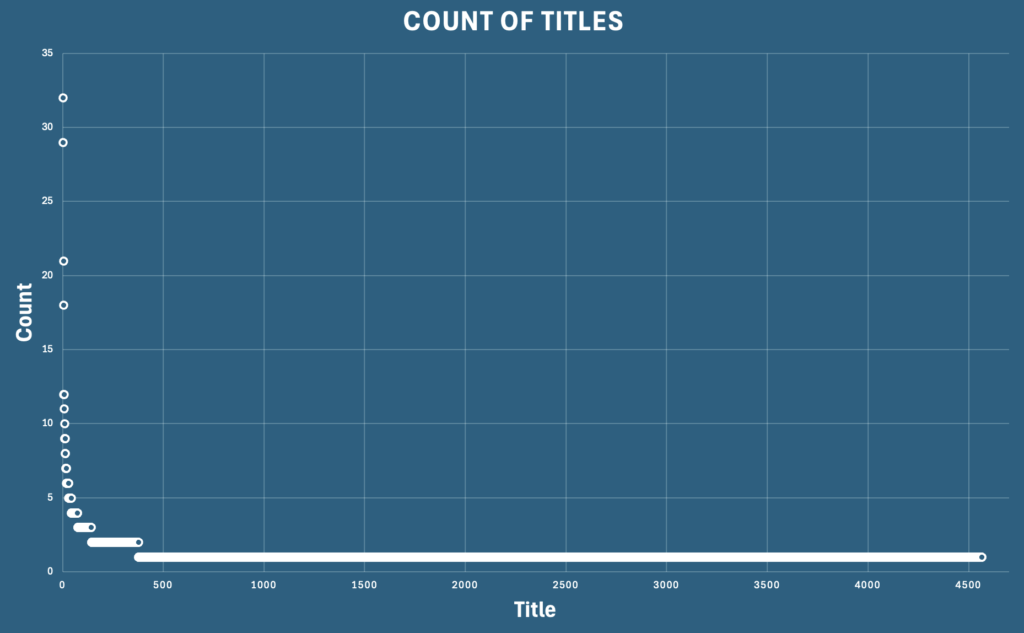
Schauen wir uns zunächst die meistgenannten Titel an. In den TOP 20 ist eine Liste von sehr bekannten Büchern, aber die Anzahl der einzelnen Bücher deutet bereits darauf hin, dass wir es mit einer breiten Verteilung zu tun haben! Tatsächlich wurden die meisten Bücher nur ein einziges Mal hochgeladen (92%), es handelt sich also um eine Long-Tail-Verteilung. Das bedeutet, dass hauptsächlich ungewöhnliche Bücher hochgeladen werden. Die Leute, die unter dem Hashtag posten, sind weniger Mainstream, als die Top-Buchliste vermuten lässt.
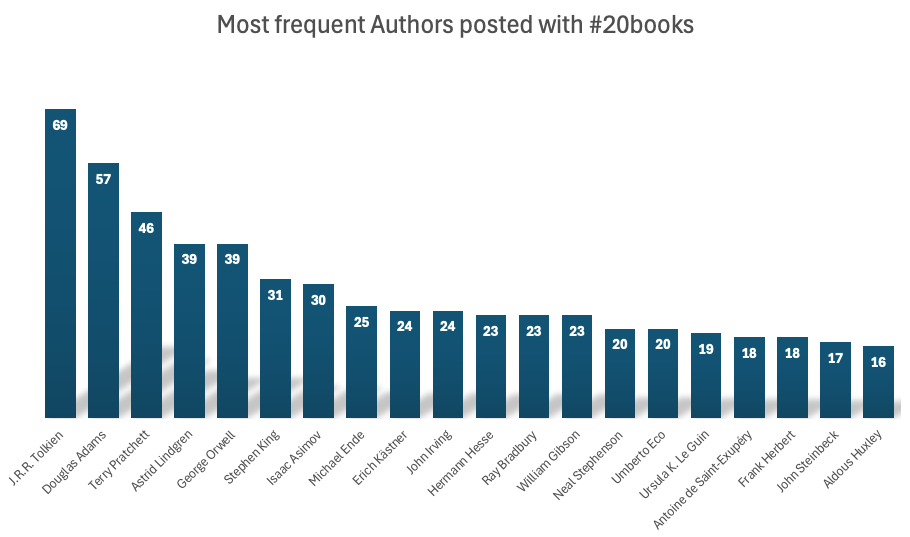
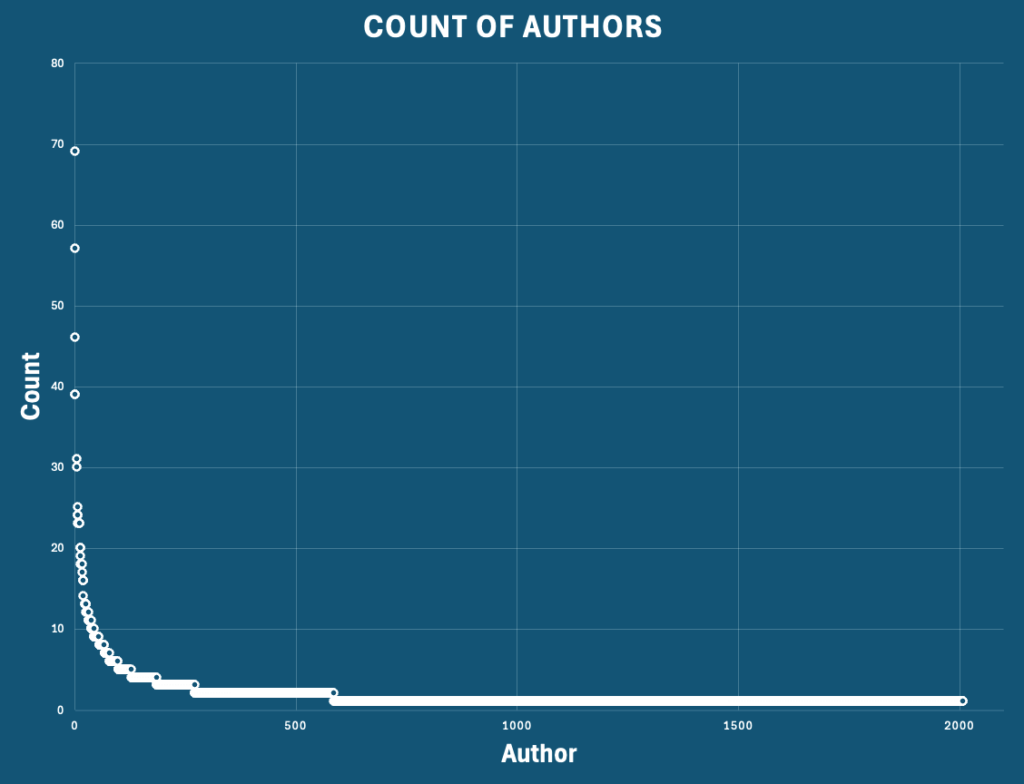
Das Gleiche gilt für die TOP-20-Autoren und deren Verteilung.
Wir können einige Unterschiede zwischen der Liste der Top-Bücher und der Liste der Top-Autoren feststellen. Zum Beispiel ist die Nr. 1 in der Titelliste – J.R.R. Tolkien – nicht die Nr. 1 in der Bücherliste. Der Grund dafür ist, dass er mehr als ein Buch geschrieben hat, das hoch bewertet wurde. Bei Douglas Adams ist das anders. The Hitchhiker’s Guide to the Galaxy war fast der einzige Titel, der genannt wurde, allerdings in verschiedenen Sprachen. Da ich das nicht korrigiert habe, werden sie als separate Bücher gezählt, siehe Einschränkungen.
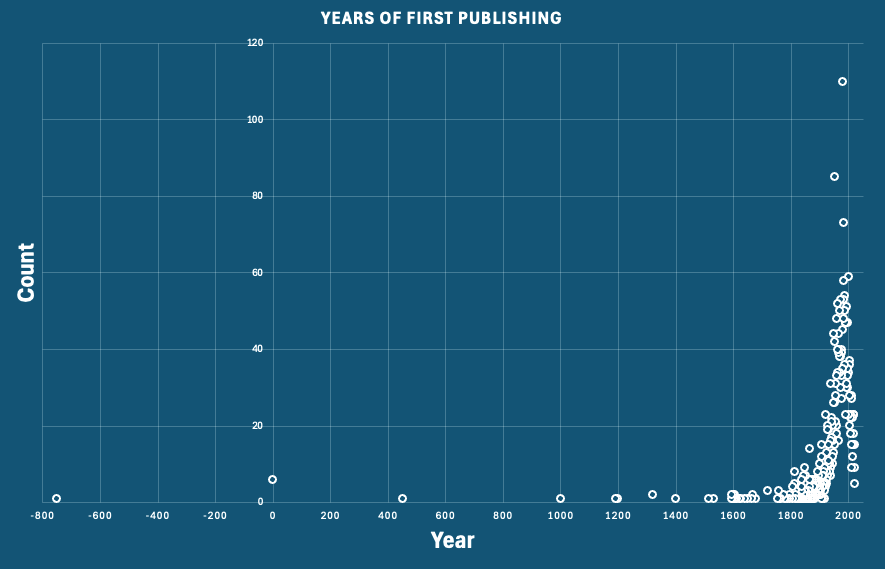
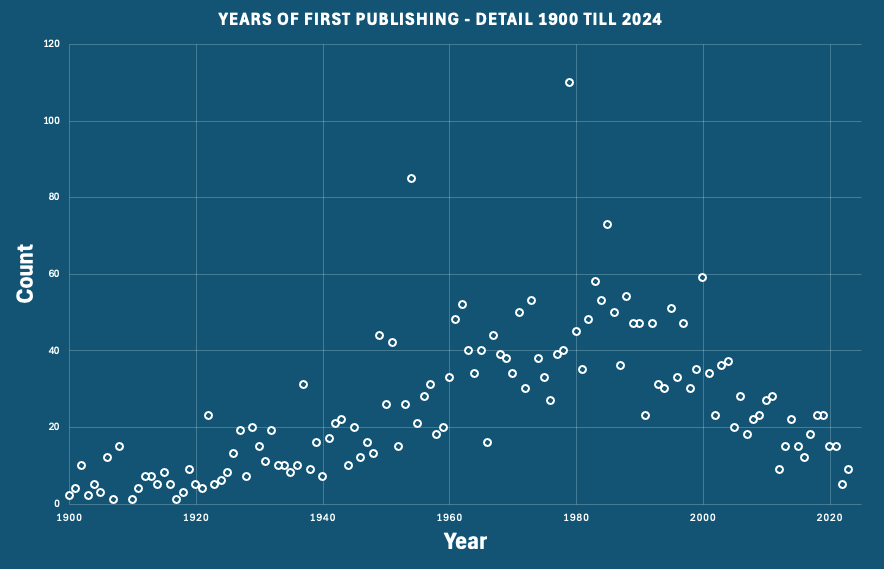
Betrachtet man die Jahre der Erstveröffentlichung, so zeigt sich ein breites Spektrum mit einer starken Häufung moderner Bücher.
Das älteste Buch, das ich fand, war Homers Ilias, das schätzungsweise 750 v. Chr. veröffentlicht wurde.
Einige Bücher wurden auf Werte um das Jahr 0 geschätzt.
Aber neuere Bücher sind eindeutig die Favoriten der untern #20books postenden Leuten mit einem ausgeprägten Maximum zwischen 1960 und 2000.
Aus den Genre oder Sub-Genre konnte ich nichts herauslesen.
Alle Daten
Wenn du die Liste durchgehen und nach Genres oder Autoren usw. suchen möchten, können du die extrahierten Daten hier herunterladen:
https://github.com/HenningVajen/20books_mastodon
Es sind alles .csv-Dateien, die leicht in Tabellenkalkulationsprogramme wie Excel oder Numbers importiert werden können.
Wenn du etwas aus den Daten machst, freue ich mich über eine Info.
