
Generative Künstliche Intelligenz (GenAI) wurde schon häufig gelobt oder aufgrund schlechter Resultate verissen. Vieles scheint von der Aufgabenstellung abzuhängen. Ich versuche es für Tabellierung von Büchern zu verwenden, für die nur Fotos von den Covern vorliegen – und zwar 6500 Fotos! Händisch hätte die Aufgabe sicher niemand gemacht.

Die Aufgabe
Ich habe mich mit der Analyse eines Hashtags auf Mastodon zum ersten Mal große Datenmengen an ein LLM (ChatGPT 4o) übergeben. Das Ziel war der Hashtag #20books auf Mastodon unter dem tausenden Bücher gepostet werden die den Nutzern dort besonders beeinflusst haben.
Es war sehr leicht an die Inhalte zu kommen, die Analyse hatte ihre Tücken, die ich hier beschreiben möchte.
Hier ist schon einmal der Link zur Auswertung der Bücher:
https://digi-ing.de/finding-cool-books-on-mastodon-by-analyzing-over-6000-posts
Die Vorgehensweise
Die meisten Mastodon Instanzen haben eine REST API über die einzelne Posts, Toots genannt, abgefragt werden können. Das habe ich für den Hashtag „20books“ getan und eine ordentliche Anzahl an Resultaten bekommen:
number of toots processed: 6682
number of toots with media: 6376
number pictures: 6543Somit liegen also ca. 6500 Bilder von Buchcovern vor, die nun mit ChatGPT analysiert werden können.
Testen im Playground – beeindruckende Resultate
Ich habe zunächst mit wenigen Büchern im Playground getestet bis ich eine Promt hatte, der für diese Bücher tolle Resultate geliefert hat.
Der Promt:
You are an assistant for the task of extracting information form pictures of book covers. You will receive images of book covers. Please analyze the picture to identify the following details: 1. The author’s name, 2. The book’s title, 3. The date of first publishing, 4. The genre and 5. sub-genre. Create a confidence score from 0 (just a guess) to 100 (absolutely certain) that describes how confident you are in the accuracy of the details identified. Add the score to details analyzed. Output the results as a .csv. No other text output. All in one line. No Header of the csv. Values shall not be embedded in apostrophes. date format yyyy. If you cannot identify a book in the picture return the Text: No Value extraction possible“
Selbst bei schwierigen Fällen wurden beeindruckende Resultate geliefert.
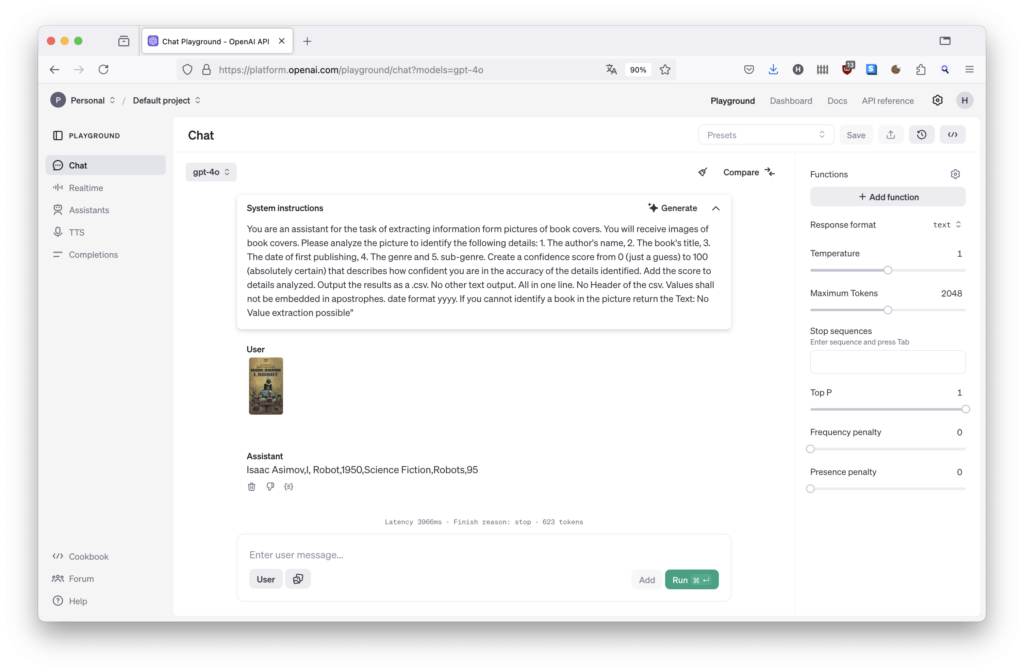
Letztlich ist die Aufgabe „Erkenne den Inhalt des Bildes und Suche nach den Metadaten“ und diese kennt das LLM sicher. Im Internet sind schließlich alle diese Bücher vorhanden.
ALL IN: Alle Bilder auswerten – Ernüchterung
Ermutigt von den guten Resultaten habe ich nun alle 6500 Bilder über die OpenAI API zur Analyse gegeben. Nach einigen Stunden waren nicht nur die Ergebnisse sondern auch eine Ernüchterung vorhanden. Traten einige Abweichungen auf, die ich im Nachgang – teilweise komplett manuell – korrigieren musste. Ich habe die Probleme in drei Kategorien zusammengefasst.
Fehler Kategorie 1) Unterschiedliche Schreibeweise für dieselben Begriffe
Bei jeder Analyse wird zufällig eine Schreibweise von den immer gleichen Begriffen produziert. So wird aus „Non-Fiction“ zum Beispiel „Nonfiction“ oder „Non Fiction“. Es tauchen auch „Moby-Dick“ und „Moby Dick“ auf. Das stört den menschlichen Leser nicht, macht aber für eine statische Analyse, wie ich sie vorhabe erhebliche Schwierigkeiten.
Absolut ernüchternd sind die unterschiedlichen Rückgaben, im Falle eines nicht zu ermittelden Datums – es wurden 65 unterschiedliche Begriffe für diesen identischen Sachverhalt zurückgeliefert!
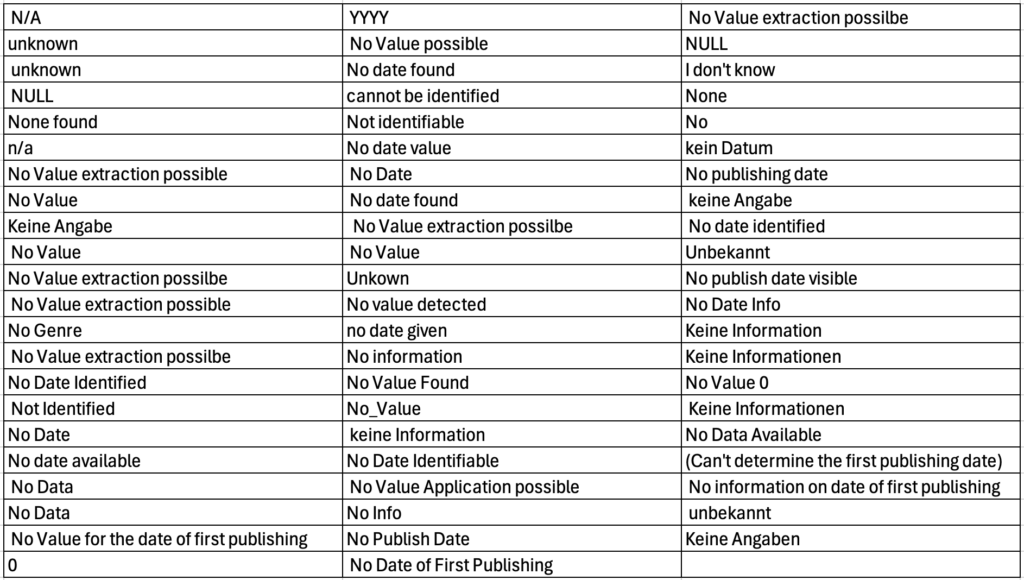
Fehler Kategorie 2) Fehler in der Ausführung des Promts: Kommasetzung im csv nicht durchgängig
Ca. 150 Einträge wurden komplett ohne Kommas gesetzt, andere sind haben zu viele oder zu wenige Kommas. Das macht sich bei der Erstellung von csv-Daten (ausgeschrieben Comma-separated values!) nicht gut.
Fehler Kategorie 3) Ignorieren des Promts: Reihenfolge oder Syntax der Resultate wird immer wieder verändert
Es werden z.B. drei Genreunterteilungen zurückgegeben, wo nach zweien gefragt wurde oder es werden mehrere Autoren mit Komma separiert, wo nur ein Wert für Autor vorgesehen ist.
Teilweise werden die Parameter zusammen mit den Resultaten ausgeschrieben, z.B. „Sub-Genre: Comic“.
Das Schlimmste jedoch ist die Vertauschung von Titel vor Autor bei hunderten Einträgen. Das ist schwer zu korrigieren und kommt häufig vor.
Geht das nicht besser?
Wenn ich die Aufgabe nochmal starten würde, würde ich insbesondere zwei Dinge verändern:
Erstens, eine sofortige Überprüfung der Rückgabe. Falls z.B. der Syntax nicht stimmt, wird das Resultat gelöscht und einfach nochmal mit den gleichen Daten gefragt. Das führt zwar zu einem höheren Tokenverbrauch, sollte aber die Nacharbeit reduzieren.
Zweitens, macht es Sinn ChatGPT sich selbst optimieren zu lassen. Also Fehler sammeln und nach einem verbesserten Promt fragen. Ich habe das getan und mir wurden unter anderem eine bessere Strukturierung der Rückgabewerte und das Ergänzen eines Bespielresultats vorgeschlagen:

All das verbessert die Qualität, kann aber nicht alle der oben genannten Problem lösen.
Fazit
GenAI ist ein spannendes Werkzeug. Es macht Arbeiten möglich, für die sonst niemand Zeit hat, oder hättest ihr euch hingesetzt und 6500 Buchcover handisch tabelliert?
Die Kontrolle der Resultate mit großer Sorgfalt ist jedoch unerlässlich. Dafür müssen ein erheblicher Zeitaufwand und Ressourcen eingeplant werden. Kontrollmechanismen sollte man mitdenken und in den Ablauf der Bearbeitung einbauen, wo immer es möglich ist.
Ich hatte durchaus Spaß mit diesem Mini-Projekt und finde es Ergebnis auch ganz nett
