Beim Unsupervised Learning („Unüberwachtes Lernen“) wird keine Antwort vorgegeben. Die Daten die übergeben werden, müssen also nicht logisch gegliedert sein.
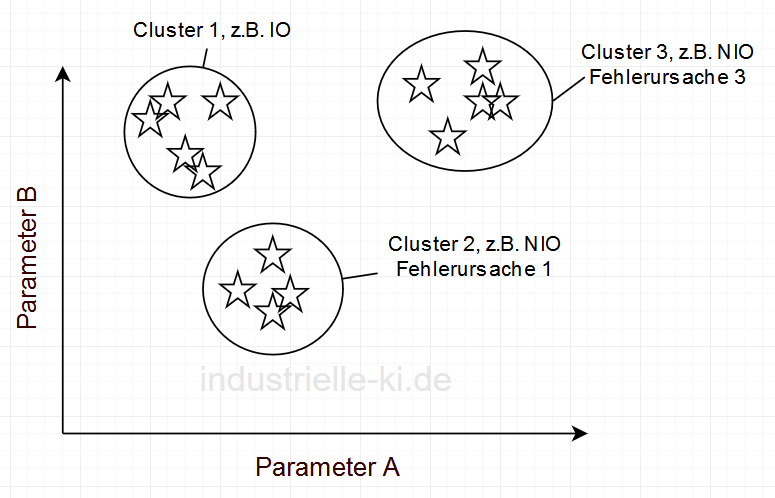
Das Ziel dieser Vorgehensweise ist es ähnliche Elemente zu gruppieren. Man spricht von Clustern. Auch für diese Vorgehensweise gibt es zahlreiche Anwendungen, wie Nachrichtenartikel zum selben Thema zu präsentieren oder Personen mit ähnlichen Interessen in sozialen Netzwerken einander bekannt zu machen. Die Kriterien der Clusterung müssen dabei nicht bekannt sein, sondern werden erlernt. Die Interpretation muss im Nachgang mittels menschlichem Expertenwissen erfolgen. In unserem Beispiel aus der Leiterkartenproduktion (zur Einführung in das Beispiel siehe den Beitrag über Supervised Learning) können so unterschiedliche Fehler unterschiedlichen Parametern der Fertigung zugeordnet werden, wie die Abbildung verdeutlicht. Auch hier gilt, die Anzahl der Parameter wird nicht durch die Methode begrenzt.